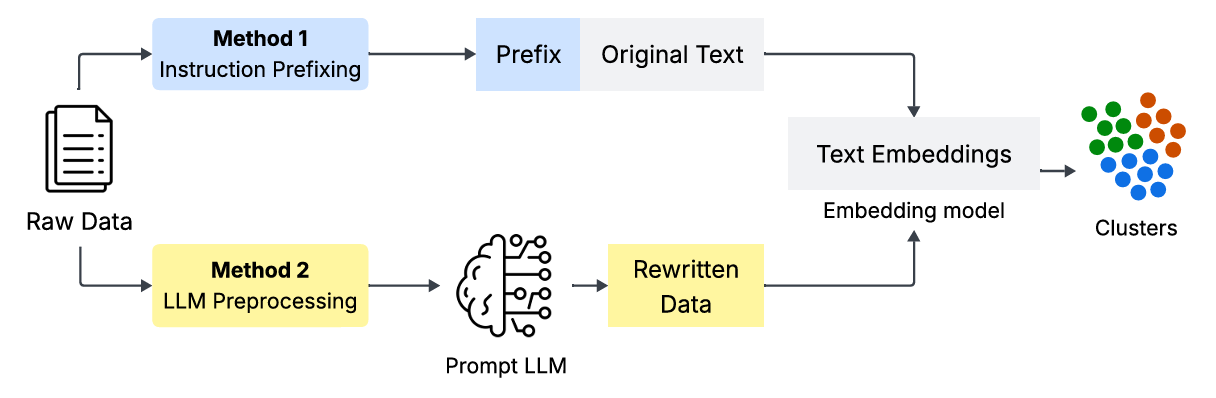
Controllable Clustering with LLM-driven Embeddings
Given the inherent subjectivity of similarity in text, fully unsupervised text clustering is unlikely to produce groupings that are relevant across a variety of use cases. Traditional techniques to guide clustering rely on costly, time-consuming human feedback and/or pre-existing labels. Leveraging recent advancements in LLMs and decoder-only embedding models, this project presents techniques to effectively control text embeddings with minimal human input: instruction prefixing and LLM preprocessing. We evaluate clustering performance for datasets with multiple independent ground-truth labels, or perspectives, and find that these techniques can be used to improve clustering for one perspective or use case, at the cost of a tradeoff in performance for another use case.